|
EXCEL版数量化理論Ⅲ類による分析について
~ SPSS/PASWにおける分析との対比 ~
EXCEL版の数量化理論ソフトを使っている方から、SPSS/PASWではなくEXCEL版数量化理論Ⅲ類による分析例を載せてほしいという要望がありました。最近はSPSS/PASWでの数量化理論ソフトが販売停止らしく、EXCEL版に対応する必要が出てきていました。
作業が遅れておりましたが、簡単な分析例を示してEXCEL版での分析について説明を追加致します。
*利用ソフトはWindows版「EXCEL数量化理論Ver.2.0」Excel2000/2002/2003/2007/ 専用」
使用しているOSはWindowsXP(SP3)及びソフトはExcel2000です。
(6/28, 2012)
このサンプル・データは [数量化理論Ⅲ類による本文中の図についての補足]に掲載しています。そちらでは、SPSS/PASWでの分析の実例を説明しています。
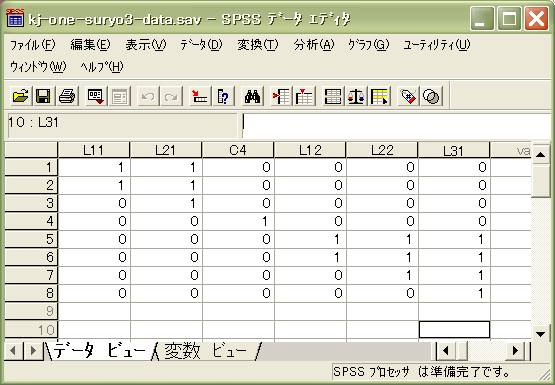
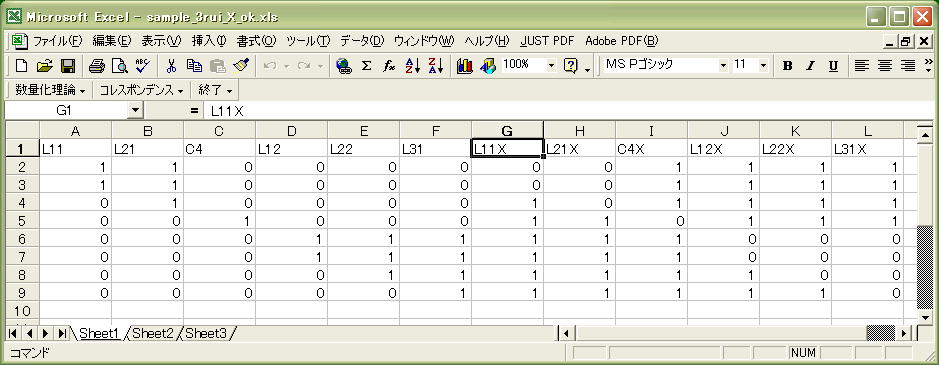
元のデータは上の内容ですが、SPSS/PASWでの数量化理論Ⅲ類の分析では、実際には、以下に示すようにExcelファイルの右半分に新しいデータを追加したものを分析対象にしています。
●例えば、「L11x」というカテゴリー・ラベルに該当するカードは、「L11」というカテゴリー・ラベルに含まれないカードすべてです。また、「L21x」というカテゴリー・ラベルに属するカードは、「L21」に含まれないカードすべてです。右半分の追加データは、このように、L11 L21 C4 L12 L22 L31 のそれぞれのカテゴリーに含まれないものから構成されるカテゴリーとして新規に追加されています。
SPSS/PASW版の数量化理論Ⅲ類の分析で、なぜこのようにして分析しているのかは[数量化理論Ⅲ類による本文中の図についての補足]で解説していますが、まずはこのデータをExcel版数量化理論Ⅲ類によって分析してみることにしましょう。
 ここではExcel2000を用いています。「数量化論Ⅲ類」をクリックします。 ここではExcel2000を用いています。「数量化論Ⅲ類」をクリックします。
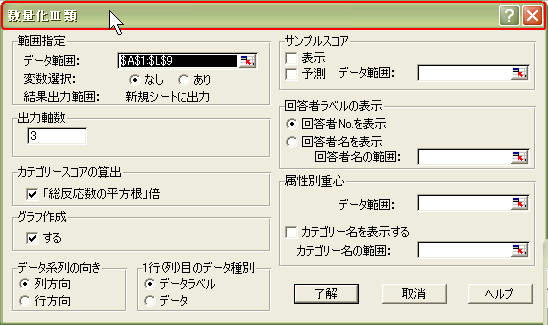
[範囲指定] 「データの範囲」(A1~L9)を決めます。
Excel版数量化理論では、「データ」の1行目にラベル名を記載できるので、1行目のデータ・ラベルまでも含めて「データの範囲」として指定します。
これは下にある「1行(列)目のデータの種別」の選択肢で「・データラベル」と指定しておきます。
「出力軸数」はとりあえず{ 3 }などの数値を入れておきます。
「カテゴリースコアの算出」もチェックしておきます。
「グラフ作成」も「・する」と設定します。
「データ系列の向き」は「・列方向」と横一列にデータが1ケース分のデータが並んでいることを指定します。
(サンプルスコアはKH法では使わないので、右側半分はとりあえずそのままにしておきます)
「了解」をクリックすると、グラフの設定画面が出てきます。
「点グラフ」は普通の縦横十字のグラフなので選んでおきます。
「カテゴリー名の表示」も選んで、図にカテゴリー(ラベル)の名前が表示されるようにします。
「了解」をクリックして計算を実行させます。
Excel版数量化理論Ⅲ類による分析結果
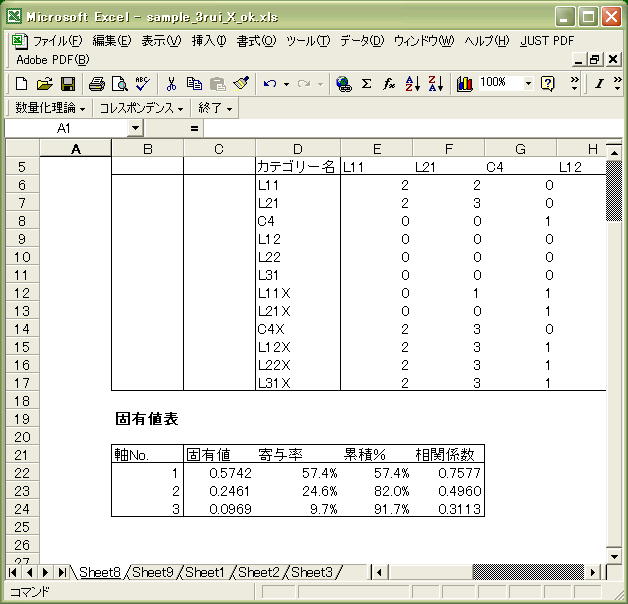
Excelに新しいSheetが追加され、クロス集計表と固有値表が表示されています。
(ここではSheet8ですが状況により異なります)
固有値が大きいほど、その軸によって説明される度合いが大きく、ここではⅠ軸の寄与率が57.4%、
Ⅱ軸の寄与率が24.6%、Ⅲ軸の寄与率が 9.7%となっています。
(なお、相関係数の二乗が固有値に等しい)
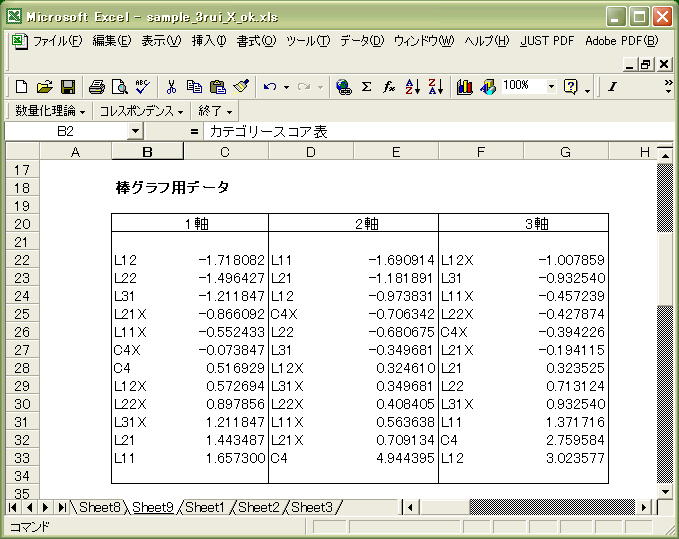
カテゴリー・スコア表では、カテゴリーのそれぞれが第Ⅰ軸・第Ⅱ軸・第Ⅲ軸でどのような数値となっているかが表示されています。
見えませんが、右側にはこれに基づいた「点グラフ」も表示されています。
第Ⅰ軸、第Ⅱ軸、第Ⅲ軸それぞれにおいて、L12 L22などのカテゴリー・ラベルに振り当てられたカテゴリー・スコアにしたがって、それぞれのカテゴリー・ラベルを軸にプロットしていきます。
各軸の両端に位置するカテゴリー・ラベルに基づいて、その軸に意味づけをして命名していきます。
この結果は、 [SPSSでの分析結果] と一致しています。確認してみてください。
●なぜこのような分析を行うのか
数量化理論Ⅲ類による分析では、項目数が極端に少ない場合や、ケースとラベルの対応関係が特殊な場合、そして特にKH法で得られる「カードとラベルの対応表」では、固有値計算にエラーが出る場合があることを経験的に確認してきています。
普通は固有値の数値が、第一固有値、第二固有値、第三固有値の順に「0.753, 0.531, 0.332…」などのように小さくなるのですが、何らかの計算エラーがあると、それがたとえば「1.000, 1.000, 1.000…」などと明らかにおかしい結果となります。(EXCEL数量化理論Ⅲ類では必ずしも「エラー」と明示されないので注意。)
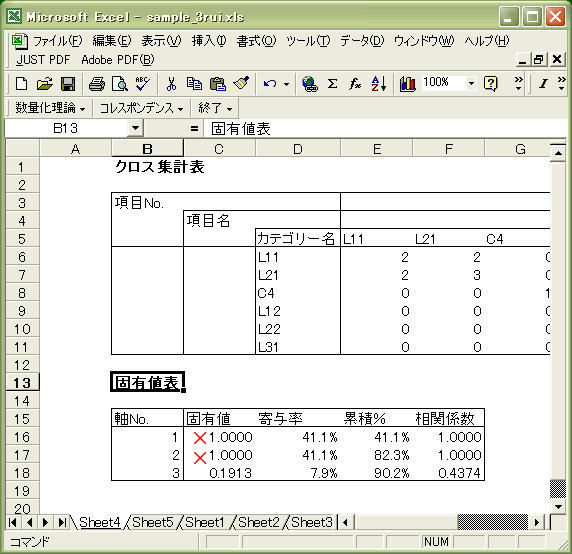
ちなみに、「L11x L21x 」などのカテゴリー・ラベルを導入しない元のデータのままでExcle版数量化理論Ⅲ類で分析すると、このように固有値が{ 1.0000 1.0000 …}といった異常な数値となります。これでは軸の解釈には使えません。
この数値ではダメなので間違わないように × を付けておきました。
ところで、元々、SPSS版の数量化理論Ⅲ類のソフトでは、「変数の最小値・最大値設定」のところで、最小値{0} 最大値{1}と設定できるようになっていて、実はこのように設定すると、結果的に上に示したExcelデータのように「L11 L21 C4」だけではなく、「L11x L21x C4x」といったカテゴリー・ラベルとそのデータを自動的に追加した形で分析するようになっています。
このように分析すると次のようなメリットとデメリットがあります。
- メリット : 固有値の計算自体でエラーが起きることが極めて少なく、分析結果が容易に得られる。したがって、軸の意味づけや命名を行うことができる。
- デメリット:カテゴリー・ラベルの個数を実質的に二倍にしたため、そうでない場合と比べて最大固有値の大きさが数十%程度も小さくなる。
KH法では、自由記述内容などをカード化して集約したものに何らかの軸や次元を見いだすために数量化理論Ⅲ類を利用します。得られた軸・次元の両端に位置するカードやラベルの意味内容に基づいて、因子分析で行うように、軸や次元に名前をつけます。その際、軸の両端に位置するものに基づいて判断するため、軸の中央、原点付近のカードやラベルはあまり関係がないのです。
たとえば「L11」についてのデータと正反対のデータをもつ「L11x」は軸の両端に寄ることはなく中心の原点付近に位置します。つまり、「軸の解釈と命名」に「L11x」などの" x "のついたカテゴリー・ラベルは関与しないので特に問題にならないのです。
デメリットとしては、カテゴリー・ラベルの数が二倍になり、得られる最大固有値の値も必然的に低下するため、その軸の重要性についての議論が難しくなります。ただし、数量化理論Ⅲ類の利用は、統計的な意味合いでの利用ではなく、質的データである記述の集約内容に何らかの構造を数理的に見いだすことに主眼があるため、それほど大きなデメリットではないと判断しています。
通常の分析で特にエラーが出ないようなデータ内容であれば通常の分析を進めれば良いですが、SPSS/PASWを前提としたアプローチでは、すでに示した分析上の手法は、数量化理論Ⅲ類による分析を進める際のオプションという位置づけにあります。KH法による言語的記述内容の集約の結果、「ケースとカテゴリーの対応表」がある特異の構造をもち固有値計算ができない場合があるため、その問題を回避するための手段…ということなので、ここから先は分析方法、分析手法について研究者の考え方やスタンスの問題だと言えるでしょう。
なお、これまでの経験から、言語的記述の集約結果を数量化理論Ⅲ類を用いて分析するというKH法のアプローチはかなり有効であるという手応えを感じて今日に至っています。そのため、これまでに示してきた手法はそれを実現するための分析上の一方法として有効と考えています。
|