■ 分散分析(一元配置)の事前の分析
- 一元配置の分散分析とは、一つの要因があり、その要因に複数のグループ(水準・群)があるとき、各グループ毎の平均値が有意に異なっているかどうかを分析するものです。グループが二つならば「平均値の差のt 検定」で分析しますが、三つ以上になると、グループを二つずつ取り出してt 検定していくのでは問題があるため分散分析を用いることになります。(分散分析の多重比較がなぜ必要なのかに関わります)。
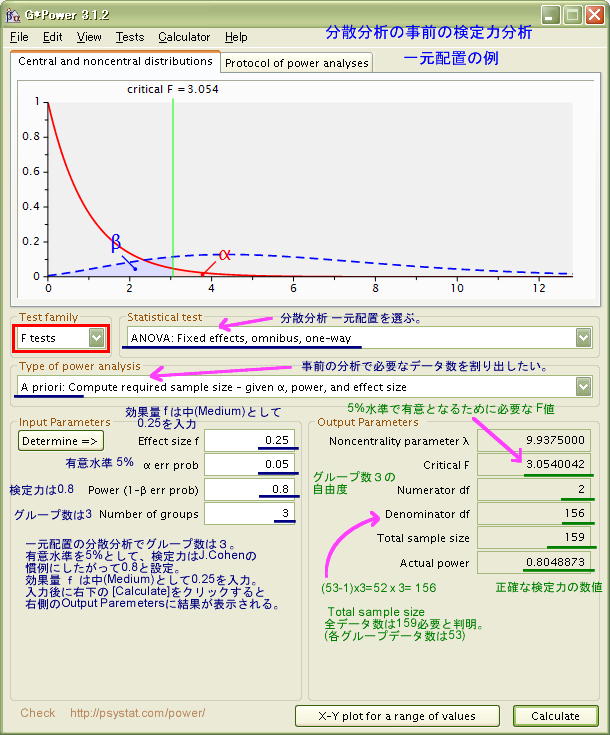
検定力の事前の分析では、必要なデータ数Nを調べるために、[有意水準α、 効果量ES、 検定力(1-β)]の三つの数値を設定する必要があります。ここでは、有意水準αは0.05 (5%)と設定します。検定力Powerは、J.Cohenによる慣例で(1-β)=0.8 と設定します。そうすると、最後に残るのが「効果量 ES: Effect size」となります。
J.Cohen(1992)では「効果量 小(Small)=0.1、 中(Medium)=0.25、 大(Large)=0.4」を慣例(convention)として提唱しています。
* ここで効果量の式(母集団における効果量)は以下のように示されています。
- f=σm/σ
ただし、σmは母集団での平均値の標準偏差。σはグループに共通の母集団内標準偏差
- 実際のデータを用いて算出する標本効果量の式は次のようになっていて、各水準の平均値が相互に異なっている度合い(水準間平方和)を評価していることが分かります。(G*Powerソフトが自動的に計算します)
- f =√ [(水準間平方和)/(水準内平方和)]
以下にJ.Cohenによる表を抜粋します。その下にあるのは、G*Powerソフトで分析したもので、いずれも同じ設定における「必要なデータ数」を示しています。なお、J.Cohenの表では、常に「それぞれのグループの度数」を表示していて、G*Powerソフトでは、全データ数(Total sample size)となっているので注意してください(参考までに各グループ毎のデータ数も括弧内に表示してあります)。
分散分析ANOVAの検定力分析:必要なデータ数
* J.Cohen (1992)のTable2から抜粋
|
α=0.05、 Power=0.80 |
| Effect size 効果量→ |
Small |
Medium |
Large |
| 2 groups |
393 |
64 |
26 |
| 3 groups |
322 |
52 |
21 |
| 4 groups |
274 |
45 |
18 |
| 5 groups |
240 |
39 |
16 |
| 6 groups |
215 |
35 |
14 |
| 7 groups |
195 |
32 |
13 |
分散分析に必要なデータ数 Total sample size
G*Powerソフトによる結果
合計データ数 (各グループのデータ数)
|
α=0.05、 Power=0.80 |
| Effect size 効果量→ |
Small (0.10) |
Medium (0.25) |
Large (0.40) |
| 2 groups |
786 (393) |
126 (63) |
52 (26) |
| 3 groups |
969 (323) |
159 (53) |
66 (22) |
| 4 groups |
1096 (274) |
180 (45) |
76 (19) |
| 5 groups |
1200 (240) |
200 (40) |
80 (16) |
| 6 groups |
1290 (215) |
216 (36) |
90 (15) |
| 7 groups |
1372 (196) |
231 (33) |
98 (14) |
- J.Cohenの必要なデータ数の表とG*Powerによる分析結果では、度数に±1程度のずれが確認されますが(小数点以下の丸めの誤差)、基本的な結果は同じです。なお、J.Cohenの表はどの分析の場合も「それぞれのグループの度数」が表示されているのに対して、G*Powerの結果は「Total sample size」であり全データ数が表示されます。
なお、上に二つの表はいずれも、有意水準α=0.05、検定力Power(1-β)=0.8、効果量 f =010(小)、0.25(中)、0.40(大)、と設定した際に必要なデータ数の表となっています。
G*Powerソフトの設定方法を以下に示します。
■ 一元配置分散分析をG*Powerで事前分析する。
- グループ(水準)が三つある場合、それぞれの平均値のズレが中程度( f = 0.25 )の場合、各グルーブのデータ数はそれぞれ53、全部で159個のデータが必要と分かりました。ちなみに、検定力を少し下げて Power=0.70に設定してみても、必要なデータ数は三つのグループそれぞれに43、合計で129個が必要ということも算定されます。
研究の内容上、そこまでデータ数を揃えるのが難しい場合は、効果量がもっと増えるように、水準毎の平均値の差がもう少し多くなり、同時に水準内の分散も小さくなるように、研究の設計を再検討する必要がありそうです。仮に効果量が大( f =0.4)となれば、α=0.05、Power=0.8 であっても、必要なデータ数は3グループがそれぞれ22、全部で66個で間に合うことが計算されるからです。
|
■ 分散分析(一元配置)の事後の分析 (Post hoc analysis)
- 一元配置の分散分析とは、一つの要因があり、その要因に複数のグループ(水準・群)があるとき、各グループ毎の平均値が有意に異なっているかどうかを分析するものです (2グループしかないときは平均値の差のt 検定で行い、3グループ以上あるときは一元配置の分散分析を用います)。
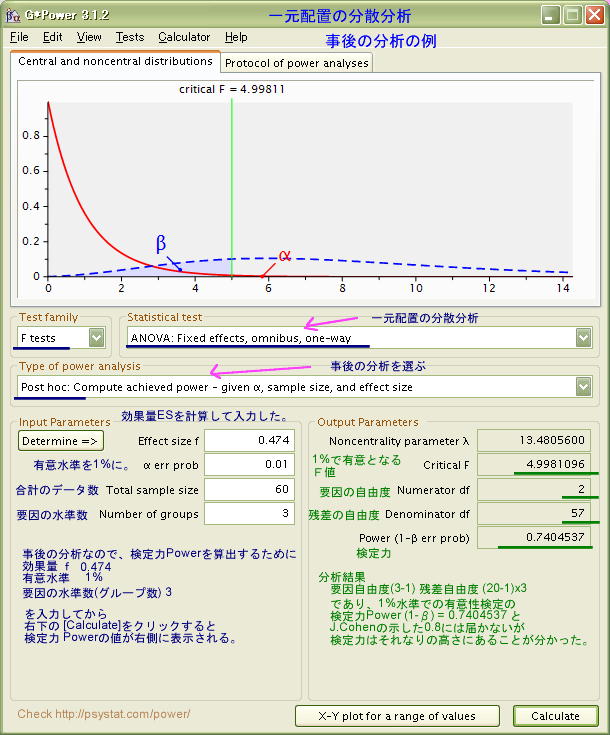
事後の分析は、研究を終えた後に、用いた有意性検定にはどの程度の検定力があり、得られた結果をどの程度強く主張できるかを明確にするために行います。
検定力の事後の分析では、[有意水準α、 各グループのデータ数、効果量ES」の三つの数値から 「検定力Power (1-β)」の大きさを割り出します。データ数は複数あるグループ毎に同じ場合とそれぞれ異なる場合がありますが、そうした実際の数値(全データ数)を用います。効果量ES (Effect Size)は、帰無仮説と対立仮説とのズレの大きさのことですが、帰無仮説「各グループの平均値はすべて等しい」と対立仮説「各グループの平均は必ずしも等しくない」を対比したときに、各平均値が相互に大きくずれていると「効果量が大」、小さなズレのときは「効果量が小」となります。
分散分析の効果量ES f は、事後の分析の場合、分散分析表に表示されている数値から計算することができます。F値や(標本)相関比を用いた計算方法などの詳細は豊田秀樹『検定力分析入門』で説明されています。分散分析表に示されている「要因の平方和(水準間平方和)」と「誤差の平方和(水準内平方和)」を用いた式は「事前の分析」でも示しましたが、以下に再掲します。
- 分散分析の効果量の指標 (Effect size index): f =√ [(水準間平方和)/(水準内平方和)]
さて、事後分析のためには、以下の三つの数値を設定する必要があります。ここでは、20人かける3グループで実験をしたと想定して以下のように設定してみます。
有意水準αは0.01 ( 1%)と設定。全データ数(Total sample size)には60を入力 (20人×3グループ)。効果量 ES: Effect size f =0.474 としてみます。この効果量 f の数値は、J.Cohen(1992)の提唱する「大(Large)=0.4」を上回る数値です。
* G*Powerでは、メイン・ウィンドーの「全データ数 Total sample size」の数値を指定したグループ数で分割する際、「各グループのデータ数が均等」として計算を行っているようです。
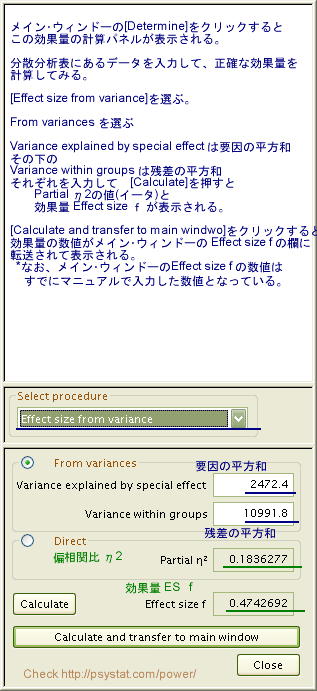
- ここで、効果量の算出用の計算パネルを表示して計算をしてみます。
効果量の計算には以下の二つの入力方法が用意されています。
- 「各グループのデータ数」「各グループの平均値」「SD σ within each group (それぞれのグループ内の標準偏差)」を入力する方法
- 分散分析表から「要因の平方和」「残差の平方和」を入力する方法
ここでは、分散分析表にある「要因の平方和」「残差の平方和」を用いる方法にしてみます。
* 平方和は豊田秀樹『検定力分析入門』にある数値を用いてみました。
Partial η2 は「偏相関比」ですが、一要因の場合は「相関比」として扱います。
過去の論文などで分散分析表が載っていればこの計算パネルを用いて効果量を算出して検定力を求めることができます。なお、表示がF値の場合は以下の式を用いて計算できます。
- f =√ [ F値×(水準間自由度/水準内自由度) ]
|
|
■ 事後の検定力分析を「分散分析表」を用いて行う
(8/29,2011追加)
分散分析表の数値を用いた場合の「事後の検定力分析」について実際のデータを用いてまとめておくことにします。(一要因分散分析と、後で示す二要因分散分析のどちらも同じデータを用いて例示します。)
ここでは例えば「要因A:年代1,2,3,4,5」と「要因B:地域1,2,3」で不安耐性について調べたとします。不安耐性の平均値が五つの年代のグループ(5水準、自由度df=(5-1)=4)と、三つの地域のグループ(3水準、自由度df=(3-1)=2)の要因によって異なるのかどうか、ということがこの「2要因分散分析」の目的となりますが、それに先だって、以下に一要因の分散分析表からG*Powerによって検定力を求める場合について解説します。
■効果量をF値から求める
(9/2, 2011)
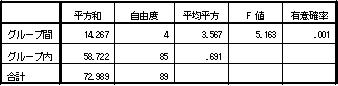
- 分散分析表の平方和から検定力を求める方法は上に示しました。しかし、論文などでは分散分析表がそのまま示されているとは限らず、多くの場合はたとえば F(4, 85)= 5.163 のように示されます (上にある要因A(年代)の分散分析表より)。ところで、F値とは次の計算式で得られる数値です。すなわち、
- F(要因の自由度、誤差の自由度) = 「水準間平方和÷その自由度」/「水準内平方和÷その自由度」
ということなので、これを用いて次の効果量の式を見直してみます。
- 分散分析の効果量の指標 (Effect size index): f =√ [(水準間平方和)/(水準内平方和)]
すると、
- 効果量 f = √ (群間自由度 / 群内自由度 × F値 )
- 効果量 f = √ (水準間自由度 / 水準内自由度 × F値 )
- 効果量 f = √ (グループ間自由度 / グループ内自由度 × F値 )
- 効果量 f = √ (要因の自由度 / 誤差の自由度 × F値 )
となります。4つの式はすべて同じことを表していますが、研究者や本などによってこのように表記が異なることがあるので書いておきます。いずれにしても、分散分析の事後の効果量を分散分析表を用いて計算できることが分かります。
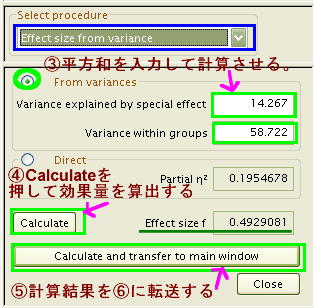
たとえば、論文などに F(4, 85)= 5.163 などのように表記されていたら、
- 効果量 f = √ (4 / 85 × 5.163 ) = 0.4929144
と計算して効果量を知ることができます。こちらの方が実際的ですね。
* 上に示した「グループ間平方和 14.267」と「グループ内平方和 58.722」をG*Powerに入力した場合の効果量 f= 0.4929081 とは計算誤差がありますが、効果量 f = 0.4929 と小数第4桁まで一致しています。
ということで、論文にF値が出ていたら、これから効果量を計算してその数値を検定力分析ソフト G*Powerに入力すると検定力が割り出せます。ところで、豊田『検定力分析入門』2009には分散分析を用いた研究について、事後の検定力分析を行っていますが、この検算のために毎回電卓のキーをたたいて計算するのが面倒になりました。ということで、分散分析表のF値から効果量を計算する簡単な電卓をプログラムしてみましたので紹介いたします。
分散分析の効果量計算電卓
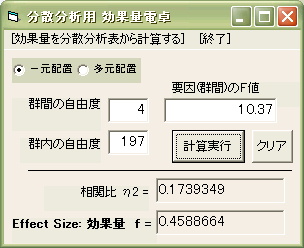
「一元配置」を選び、群間自由度 4、群内自由度 197、F値 10.37を入力して「計算実行」すると、相関比η2と 効果量 f = 0.458864 が表示されます。
なお、相関比は η2 の平方根なので、 √ (0.1739349) = 0.417055 となります。
* 「一元配置」とは「一要因分散分析」、「多元配置」とは「多要因分散分析」のことです。計算式が異なりますが、この効果量電卓で計算できます。
|