「回帰分析」の検定力分析
- 回帰分析は、臨床心理学の研究ではあまり用いられない感じがします。理由としては、アンケートによる研究やいわゆる「心理的尺度」による研究では、データは三件法や五件法などの順序尺度データ(離散型データ)が多く、実数値データをとることがあまりないためです。たとえば、[身長]=123 + b× [体重] のように、身長という実数値を体重という実数値に重み付けのbを掛けて、定数123 (a)を足して表現する―。こうした考え方が回帰分析 (単回帰分析: 身長を体重という他の一つの変数で表現する) の内容なのです。しかし、質問紙やアンケート調査のような研究が多いので、回帰分析に必要な実数値データがあまり手に入らないということです。
- y= a+b・x
y 基準変数
x 説明変数
a 定数 (直線回帰における切片の数値)
b 重み (直線回帰における傾きの数値)
例) [身長]=123 + b x [体重]
右の図では 切片a=123
|
|
実際に回帰分析を用いるのは、そうした五件法(5はい, 4, 3, 2, 1いいえ)で調べたアンケートにたとえば10個の質問があったとき (逆転項目は入れ替えをしてからですが)、全部に「はい」ならば最大50点から、最小10点までのデータを実数値のように扱うことにして「尺度値」と呼んで、この尺度値を他の尺度値で「表現する(あるいは予測する)」といった仕方で扱うときでしょう。
- * 五件法などのアンケートの順序尺度データの合計を「心理尺度」とみなして実数データ(比率尺度データ)として扱うことには原理的な問題がつきまといますが、アンケートにある程度の項目数があり、被験者数もある程度そろっている場合、「実数データ」としてみなして回帰分析を行うことはよく行われています。
なお、心理尺度についてきっちり勉強したい人は、村上宣寛『心理尺度のつくり方』北大路出版2006 が参考になります。
- 単回帰分析について
回帰分析のうち、変数を1個だけ用いて表現するとき、1個しか使わないことを特に強調して「単回帰分析」と呼びます。複数個使って予測しようとする回帰分析を「重回帰分析」と呼びますが、これと対比して用いる呼び方となります。(「重回帰」の「重」は重いのではなく複数あるという意味ですね)。
単回帰分析は、二つの変数の関係なので相関係数と密接につながっています。回帰分析では、予測するのに用いた説明変数によって、予測される側の「基準変数」がどの程度予測されたかを示す指標として「決定係数 R2」という数値が用いられます。実はこの数値は、説明変数 x と基準変数 y との相関係数rx・yの二乗になります。
- 決定係数 R2= r2x・y
決定係数は 0 から 1 までで、「説明変数によって基準変数が説明される度合い」を示します。たとえば、R2= 0.78 ならば、基準変数の数値の 78% が、説明変数の数値によって予測されることになります。そして、単回帰分析の検定力分析は、この決定係数を用いて、効果量(Effect size)は次のようになります。なお、効果量を示す式 (Effect size index) は、J.Cohenにのっとってf2 と示します。
- 効果量 f 2= R2 / (1−R2 )
さて、実際の研究に先立ってどの程度のデータ数があれば良いのかについて、事前の検定力分析で調べてみます。[α ES(Effect Size 効果量) 1-β(検定力) ] の三つを設定して、残りの変数である[データ数N]を算出するわけですが、α=0.05 などとして、 検定力としてはJ.Cohenの慣例にしたがって、 1-β=0.8 などとします。(1-β=0.7などでは、第二種の誤りの確率であるβ過誤が大きくなりすぎる、とJ. Cohenは指摘していましたね。)
残った効果量 (ES: Effect Size)ですが、J. Cohenは以下のように設定しています。すなわち―
- 「効果量 小 Small では f 2 = 0.02」 * 相関r=±0.1400
- 「効果量 中 Medium では f 2 =0.15」 * 相関r=±0.3611
- 「効果量 大 Large では f 2 = 0.35」 * 相関r=±0.5091
ここで、効果量小が見込まれるのは相関が±0.1400 程度のとき、効果量中が見込まれるのは相関が±0.3611程度のとき、そして効果量大が見込まれるのは相関が±0.5091程度のときです。
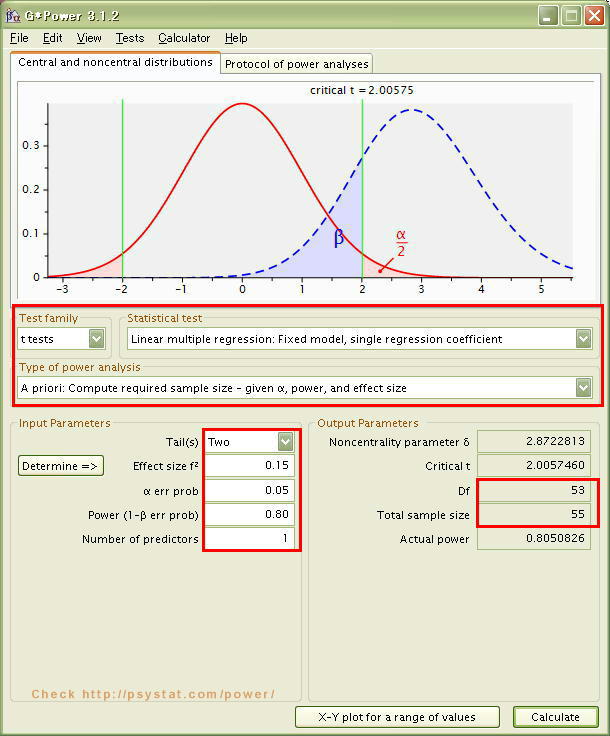
G*Powerの表示では、「ttest」「Linear multiple regression: Fixed model, single regresson coefficient」「A priori: 」を選びます。multiple regressionは重回帰のことですが、用いる説明変数を[1]に設定することで単回帰分析での検定力分析、ここでは「必要なデータ数の事前の分析」をすることができます。
設定としては、「両側検定 Two Tails」、「効果量が中 Medium 0.15 」、「α=0.05 」と有意水準を 5% と設定しています。また、検定力(1-β)は 0.8 と、J.Cohenの慣例を用いています。「Number of predictors」とは、予測に用いる説明変数の個数なので、1 と入力します。
[Calculate]をクリックすると、右側のOutput Paremeters に結果が表示されます。Df とは自由度のことで、ここでは Df = total sample size - 1 -1 です。(データ数からの -1 の他に、説明変数を1個用いているので さらに -1 としています)。 Total sample sizeが求める数値で、ここでは「 55 」と分かりました。効果量中とは相関係数が±0.3611程度の関連がある場合ということなので、その程度の相関が見込まれる場合は、データ数を55 以上とれば、有意水準 5%での検定で、検定力が 0.8 程度も得られることが分かりました。
* 図の中の「赤い四角」をクリックすると一番下に説明が表示されます。
- G*Powerによる事前分析では、回帰分析に必要なデータ数の数値は、豊田(2009)に示されている数値表と同じ数値になります。なお、効果量小( f 2= 0.02)の場合は、二つの変数の相関係数が ±0.1400 程度であることが分かっているので、このよりも低い相関では実質的に研究を進めることにあまり意味がないといえます。したがって、ここでは、効果量が中の場合 ( f 2= 0.15 、すなわち 相関係数 r = ±0.3611 ) と効果量が大 ( f 2= 0.35 、すなわち 相関係数 r = ±0.5091 ) の場合について数表を示しておきます。
単回帰分析の事前の検定力分析
必要なデータ数について
効果量 中 f 2 = 0.15 の場合
(2変数の相関 = ±0.3611)
| 検定力 (1-β) → |
0.70 |
0.80 |
0.90 |
0.95 |
| α=0.05 |
44 |
55 |
73 |
89 |
| α=0.01 |
68 |
82 |
103 |
124 |
|
単回帰分析の事前の検定力分析
必要なデータ数について
効果量 大 f 2 = 0.35 の場合
(2変数の相関 = ±0.5091)
| 検定力 (1-β) → |
0.70 |
0.80 |
0.90 |
0.95 |
| α=0.05 |
20 |
25 |
33 |
40 |
| α=0.01 |
31 |
37 |
46 |
55 |
|
この数表から、たとえば、相関係数がそれほど大きくなく例えば r = 0.36 程度と見込まれるとき、有意水準α= 0.05 の5%水準で有意となる結果が得られ、そうした「5%で有意である」という結果が検定力 0.8で得られるためには、データ数は55 以上必要であることが分かります。ここで検定力が 0.8 であるということは、すでに述べたように「5%で有意」という結果が確率0.8で得られる、すなわち100回中80回程度、そうした結果が得られることを示しています。また、相関係数がある程度高く 0.5 程度もあると予想される場合は、有意水準 5%での有意な結果が得られ、かつ検定力 0.8 を達成するためには、効果量 f 2 が中程度と考え、データ数が25 以上あれば良いことが右側の数表から分かります。
*なお、検定力分析は用いられる「有意性検定」にどの程度「検定する力」があるかを調べるものです。単回帰分析の場合の有意性検定は、「回帰係数 (y = a+ b・x の式における、傾きb)が0である」ことを帰無仮説としています。
相関の検定力分析のページにも書きましたが、MMPIなどの性格検査などの項目の相関が、例えば0.3〜0.4程度とそれほど高くない場合、データ数は55 以上必要であるわけですが、それだけのデータ数がそろえられるかどうかが要点となります。そろえられない場合は、効果量が 0.8 よりも低い0.7とか0.65とか0.60などを考えざるを得ないわけですが、そのように検定力が低い場合、得られた結果を主張する根拠が弱いという意味で「主張力の弱い研究」と留まることになります。
* ちなみに、有意水準として用いられる5%という数値は絶対的なものではなく、状況によってはそれよりも大きな0.07とか0.10などの数値を用いることが原理的に可能です。つまり、検定力が高く算出されることに関心がある場合は、有意水準のαの数値を0.05よりも大きな数値を用いることで、検定力を高い数値としては提示することが可能です。
(編集中…)
|