「関連性評定に基づく質的分析」の実際について
-分析例2-看護領域の例から
「精神科における退院をめぐる看護支援」
葛西 俊治
(元・札幌学院大学心理学部臨床心理学科教授)
ここでは、心理面接などで得られた逐語録などの言語的資料に基づいて、その内容を質的に解析していくための方法を
紹
介しています。(基本的な進め方については分析例1をご覧下さい。)
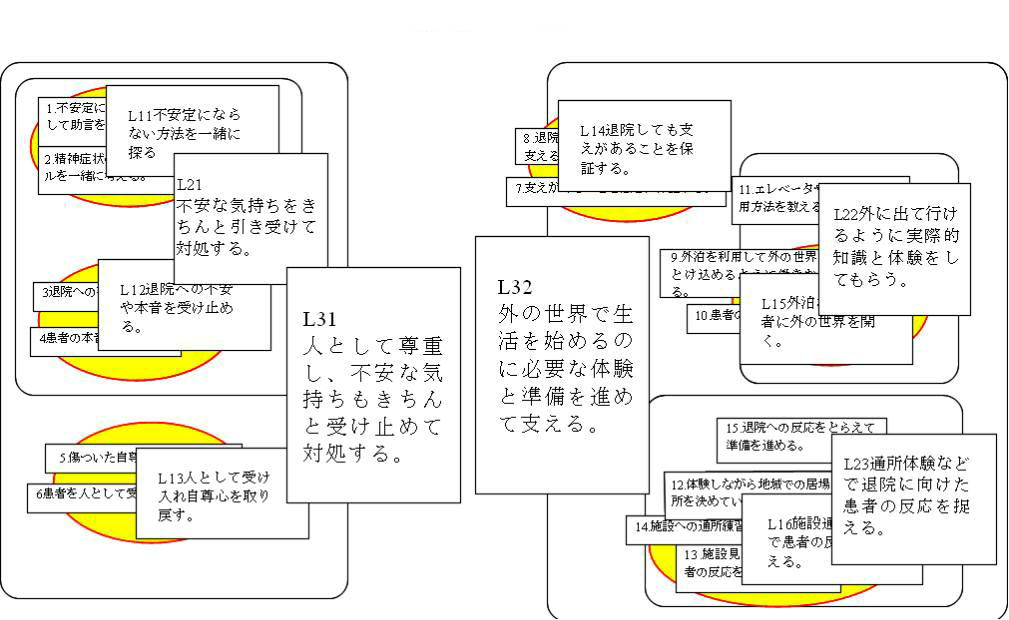
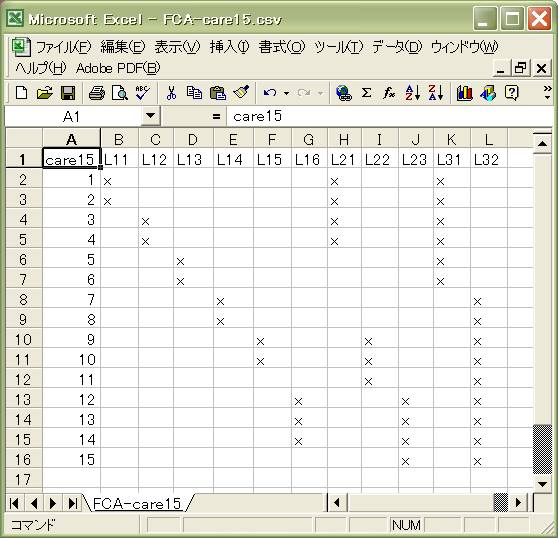
「退院をめぐる看護支援について」15枚のカードの布置
このカードは看護学領域の専門の方からのコメントを得て、KH法の進め方を例示するために私が空間配置を行ってみたものです。あくまでも関連性評定
による「空間配置・布置」の例を示すために用いていることと、私自身が看護領域の専門家ではありませんので、本来の研究内容との対応は考慮に入れていません。看護学領域ならびに心理臨床領域の研究者の方
には、こうした実際的なテーマの方が分かりやすいこともあり、例に取り上げてみたものです。
(奈良医大・佐伯恵子教授から、「精神科における退院をめぐる看護支援」に関連するカテゴリー例を列挙してもらったものを15枚のカードにしてカード布置を試みたものです。ご協力に感謝いたします。)
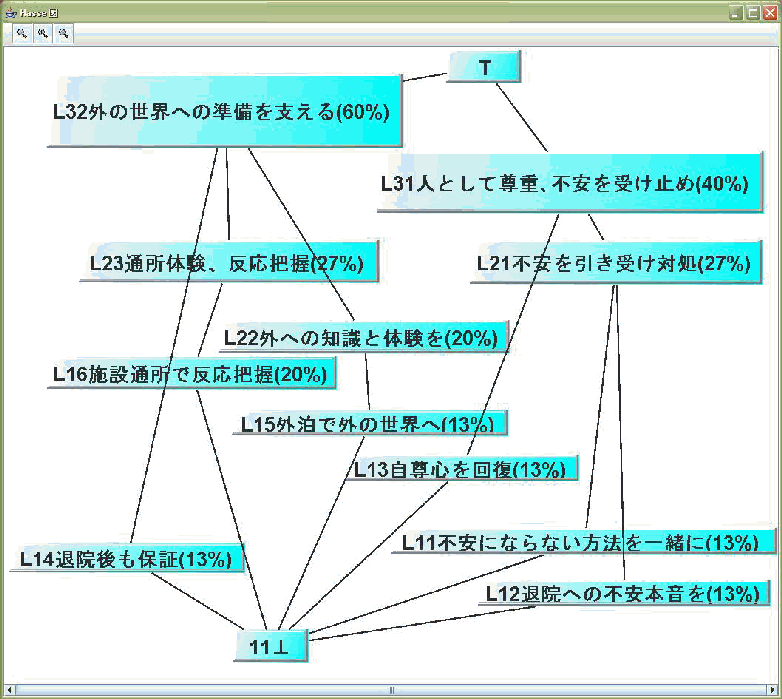
15枚のカードを対象としてそれらの「空間配置・布置」を行い、最終的には「L31 人として尊重し、不安な気持ちもきちんと受け止めて対処する」と
「L32 外の世界で
生活を始めるのに必要な体験と準備を進めて支える」という二つの大きな区域に至っています。
なお、このカード布置では、たまたま二つの大きなグループが登場しましたが、必ずそのようになるとは限りません。また、グラウンデッド・セオリーや解釈学的現象学的分析のようにグループの段階数には特別に制限はなく、テーマやカードの内容によっては5-6段階のグループも登場することもあります。
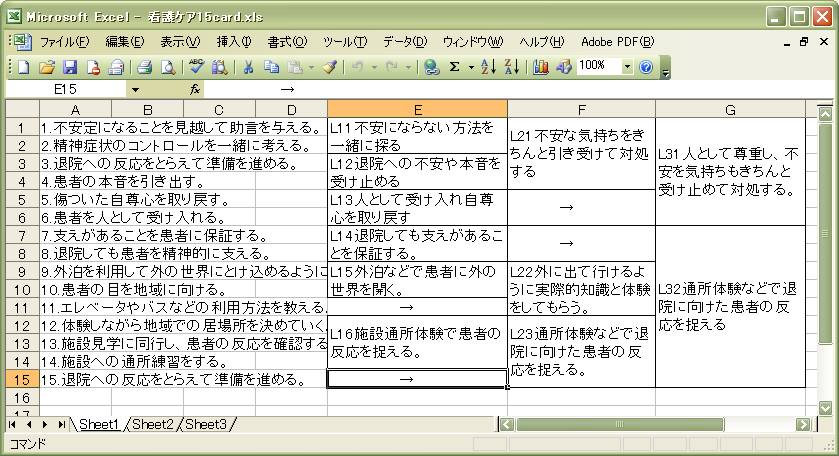
- 空間配置に基づいて、ラベルカードと独立カードの「ラベルリスト」を作る。
15枚のカードの「
ラベルリスト」
最上位ラベルカードは、L31とL32の二枚です。
その一つの下のレベルまでを見ると、
L21, L13, L31, L14, L22, L23, L32というラベルカードが取り出せます
- 「ラベルリスト」とは、図に示すように、カードが集約されてラベルの要素となっていく様子を示したものです。なお、最初に
「関連性評定」によってカードの空間配置が行われて、その結果をこうしたエクセルの表にまとめたものです。
内容はいわゆる
「クラスター分析」で出力される樹状図に似た表示となります。(カード枚数が多いときはカード全体を表示するのは大変なので、上位からいくつかのレベ
ルまでを取り上げて表示し、それ以下の個別カードやラベルカードを省略することもあります。)
- この図の「最上位ラベルカード」とは、「L31」
「L3」の二つが該当します。ただし、ここまで集約してしまうと、内容が少し抽象的になりすぎる場合や、ラベルカード数があまりにも少ない (二枚しかな
い…)場合は、その一つ下のレベルまで注目して、L21,L13,L31
L14,L22,L23,L32 の7枚を「上位ラベルカード」として扱うこともあります。
*上位ラベルカードは、逐語録などの資料の内容を代表するものとして扱います。なお、複数の人から得た個々の逐語録などの資料をカード化し空間配置を行っ
た後、そうした複数の空間配置全体の特徴を把握する際には、「空間配置のグループ化」を行う必要が出てきます。そうしたとき、それぞれの空間配置から得ら
れる「上位ラベルカード」をそれぞれの空間配置を代表するものとして取り出します。次いで、取り出したカード群全体を対象としてあらためて「関連性評定」
を行って、「グループ全
体についての空間配置・布置」を生成することになります。
その後に、数量化Ⅲ類による分析と形式概念解析による把握を行うことによって、複数の対象者全体についての「要約モデル」を得ることができます。(これ
については、別途、解説をいたします。)
- 空間配置およびラベルリストから得た「カードとラベルの対応表」を分析する。
- KJ法では空間配置図に矢印などを付加して解説を加えていきますが、「関連性評定」によって得られた空間配置図およびラベル
リストは、「関連性評定」という判断過程によってカード間およびラベル間の「関連性」が評定されてきたので、以下に示すように「林の数量化理論Ⅲ類」の入
力データとして扱うことができます。
(ここではSPSSに組み込まれたプログラムを使っているため、SPSSのデータとして示しています。数量化理論Ⅲ類は欧米では「コレスポンデンス分析」
と呼ばれる解析手法とほぼ同一の分析方法ですが、数量化理論は、以下に示すような{1,0}の対応表を直接分析するものです。林の数量化理論は1950年代に登場し、「コレスポンデンスト分析」は1980年代にヨーロッパで開発されました。なお、「林の数量化理論」プログラムはExcelの追加機能としても提供されています。)
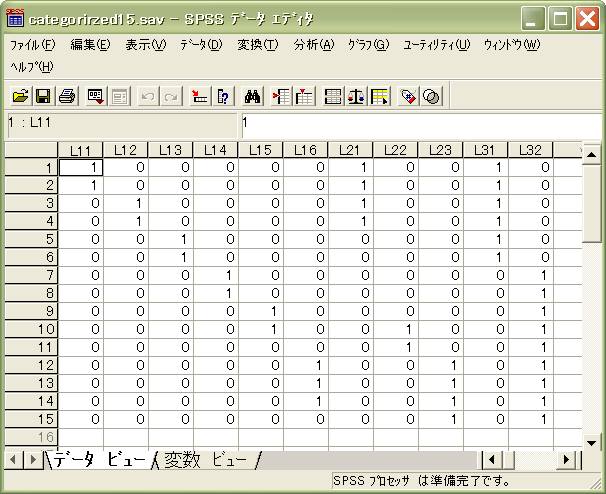
- SPSSデータエディタは、Excelと類似の行列表現となっています。各行は「カード」番号を表し、上段にある
「L11」「L21」…「L31」はラベルを表しています。それぞれのカードが該当するラベルのところには{1}、該当しないところには{0}がデータと
して入ってい
ます。これを数量化理論Ⅲ類の入力データとして分析します。
「空間配置」と「ラベルリスト」と、下に示した「カードとラベルの対応表」は互いに同一の内容で、表記の仕方が異なるだけです。
- 「空間配置」「ラベルリスト」は、いずれもカードとラベルとの関係から成り立っています。こうした形態を論理学では「束
lattice」(特に完備束)と呼びます。つまり、ラベルから成り立っている「概念束 concept
lattice」 を以下、数量化三類による次元の把握と、形式概念解析による論理構造の図示によって、より適確に把握しようとしていま
す。
空間配置図あるいはラベルリストから得られた「カードとラベルの対応表」の例
- 数量化理論Ⅲ類とは、こうした対応表があるときに、対角線上に{1}がきれいに並べられるかどうかを数理的に解析したものです。イメージ的には、行をいろいろと入れ替え列をいろいろと入れ替えをして、対角線上に{1}がきれいに並ぶような状態を実現しようとしたとき、近くにあるラベル同士には似たような数値を与え、遠くにあるラベルにはそれからはかけはなれた数値を与える…。そうしたことを数理的に(実際は固有値計算)実現したものです。
- 数量化理論Ⅲ類の計
算過程では、固有値を計算します。ここでは、第10軸までで全分散の100%が説明され、第2軸まででは全
分散の56%
が説明されることが分かります。(固有値は相関係数の二乗と等しい数値になります。)
*ここに示されている相関係数とは「ラベルに付与された数値」と「カードに付与された数値」、すわなち、列と行の項目間の相関を意味します。
詳しくは数量化理論Ⅲ類、西里の双対法、コレスポンデント分析についての専門書をご覧下さい。
固有値
相関係数 全
分散に対する累積比
1 0.37460
0.61205 0.37460
2 0.18606
0.43135
0.56066
3 0.13778
0.37118
0.69844
4 0.12037
0.34694
0.81881
5 0.10490
0.32388
0.92370
6 0.05245
0.22901
0.97615
7 0.02004
0.14158
0.99619
8 0.00381
0.06171
1.00000
9 0.00000
0.00017
1.00000
10 0.00000
0.00001
1.00000
|
- 続いて、ラベルL11,L21…L32に対する次元上の数値が「カテゴリースコア」として算出され、以下のようになります。
ここで { L11の値が
1 } というのは、そのラベルに該当するものを意味し、{ L11の値が0 }
というのは、それに該当しないカテゴリーを指し示しています。そして、L11というラベルは、第1軸と第2軸の二次元平面上では、{
-2.28878, -0.57546 } という位置にあることが分かります。
数量化理論Ⅲ類の出力
(「退院をめぐる看護支援」11個のラベル)
1 2
3 4 軸
値 カウント
L11
0. 13
0.35212 0.08853 -0.35024 -0.04
1. 2
-2.28876 -0.57546 2.27658 0.26
L12
0. 13
0.35212 0.08853 -0.35024 -0.04
1. 2
-2.28876 -0.57546 2.27658 0.26
L13
0. 13
0.19027 -0.04669 0.97020 0.28
1. 2
-1.23677 0.30346 -6.30630 -1.84
L14
0. 13 -0.14473
-0.20897 0.14166 -1.04
1. 2
0.94078 1.35823 -0.92081 6.76
L15
0. 13 -0.17967
-0.59060 -0.23807 0.43
1. 2
1.16789 3.83882 1.54749 -2.83
L16
0. 12
-0.43329 0.84502 -0.10192 0.29
1. 3
1.73315 -3.38009 0.40770 -1.19
L21
0. 11
0.83228 0.20925 -0.82785 -0.09
1. 4
-2.28876 -0.57546 2.27658 0.26
L22
0. 13 -0.17967
-0.59060 -0.23807 0.43
1. 2
1.16789 3.83882 1.54749 -2.83
L23
0. 11
-0.58244 1.04144 -0.11768 0.33
1. 4
1.60172 -2.86400 0.32363 -0.90
L31
0. 9
1.29206 0.18832 0.38959 0.29
1. 6
-1.93809 -0.28249 -0.58438 -0.43
L32
0. 6
-1.93809 -0.28249 -0.58438 -0.43
1. 9
1.29206 0.18842 0.38958 0.29
|
- 林の数量化理論Ⅲ類と
は、「質的な因子分析」と呼ばれることがあります。それは、心理学では頻繁に用いられる因子分析のよう
に、いくつかの「軸」ないし「次元」と、その次元上の位置を算出するからです。上図の上段にある「L11」「L12」…「L32」といったラベルに対し
て、それぞの次元上の座標値が得られているので、以下に簡単に図示してみます。
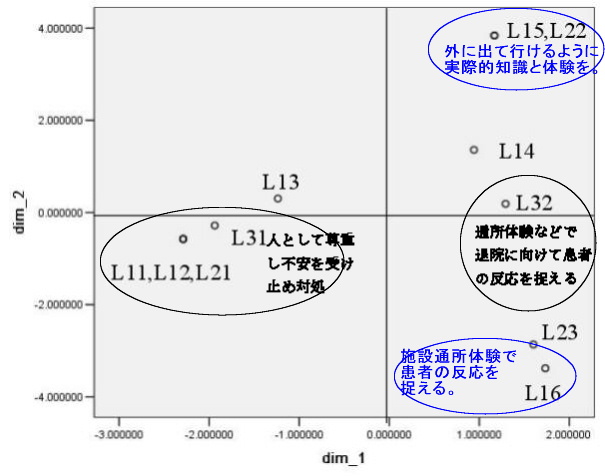
第2軸まででは全分散の56%が説明されることが上で示されています。さて、第1軸は左側空間(マイナス領域)は「L11,L12,L21」が同一の位
置を占め、そのすぐそばに「L31」「L13」があります。これは、全て、L31「人として尊重し、不安な気持ちをきちんと受け止めて対処する」という区
域に属すものです。また、右側空間(プラス領域)には、「L32」の下にあるラベルが全部含まれています。したがって、第Ⅰ軸は、「現状の気持ちを受け止
める」vs「これからの(外の世界への)準備を支える」といったような意味の軸 (ラベルとカードを丁寧に読んで、より適切な「軸の名称」を考え出す必要
があります)などと思われます。
縦軸である第2軸は、上側空間(プラス領域)には、外泊に関わる「L15,L22」「L14」…があるのに対して、下側空間(マイナス領域)には、施設
通所体験に関わる「L16」「L23」があります。したがって、第2軸は「外の世界」に関連する軸で「宿泊してから帰ってくることと、泊まらずに通うこ
と」の軸(もう少し、気の利いた命名が必要ですが…)と考えられそうです。
いずれにしても、軸の解釈は因子分析と同様に研究者によって解釈され命名されます。こうした次元表示を得ることによって、カードの空間配置の理解と解釈
の参考になる数量的把握が得られることに意味があります。
- 空間配置・ラベルリストの「形式概念解析」による図示と把握
以上、『A.逐語録の「要約モデル」の生成』の実際について簡単に示しました。従来の質的分析、たとえば、グラウンデッド・セオリー(G.T.A.:
Grounded Theory Analysis)や、解釈学的現象学的分析 (I.P.A.: Interpretative
Phenomenological Analysis)などでは、最初から最後まで、「文章」「概念」といった非数量的な内容に終始します。
それに対して、「関連性評定質的分析 R.E.Q.A: Relatedness Evaluation Qualitative
Analysis」では、「形式概念」に由来する「概念束 cocept
lattice」の構造を想定しているところに特徴があります。そして、まずは、ラベルリストに基づいて数量化理論Ⅲ類による数量的分析を行うことによっ
て、カードの空間配置の理解と位置づけに際して、数量的
分析
からの示唆を利用することができます。続いて、ラベルリストの構造は、形式概念解析によっても把握されて図示されるので、「逐語録」の「要約モデル」の構
造
が極めて理解しやすくなるという特徴もあります。
「要約モデル」の位置づけ
さて、1)逐語録のカード化、2)カード相互の関連性評定に基づく空間配置とラベルリストの作成、3)数量化理論Ⅲ類による分析、4)形式概念解析によ
るラベル構造の把握、によって、十分に検討を加えた「逐語録の要約モデル」を生成することが可能になります。こうした研究は「探索研究」「実証研究」の分
類で言えば前者の「探索研究」に該当します。探索研究とは、研究テーマに関連するモデルを提出することが主な目的となっていて、あるテーマに関する心理面
接などによって得られた逐語録は、そうした研究テーマに関するモデルを生成し提起するための素材となっている訳です。さしあたりは、「その語り手本人に
とっての個別的なあり方」に過ぎない訳ですから、得られたモデルもその個人を「個別的あり方」に関するモデルとなる訳ですが、不思議なことに、そうしたモ
デルは「その本人にしか通用しない」ような特異的で個別的な内容」だけではなく、場合によって「他の人々にも共通に見いだせそうな内容」とから成り立って
いるものです。
「解釈モデル」の生成へ
詳細な議論はここでは省略しますが、特定の状況や特定の人にしか通用しないような「周縁的要因」と一緒に、他の人々にも共通に見いだせるような「中心的
要因」とが、共にモデルの中に取り入れられている可能性があります。「中心的要因」と「周縁的要因」とは、言い換えれば「共通性」と「特異性」ということ
ですが、それを見抜いて指摘していく研究者の取り組みが、次の「解釈モデル」の生成と提起につながっていくことになります。そうした『B.「解釈モデル」
の生成』については、稿をあらためて述べることにします。
|